
Few-Shot Prompting for Flexible Classification of Operator Texts in Multilingual Aircraft Manufacturing ✈️
Published:
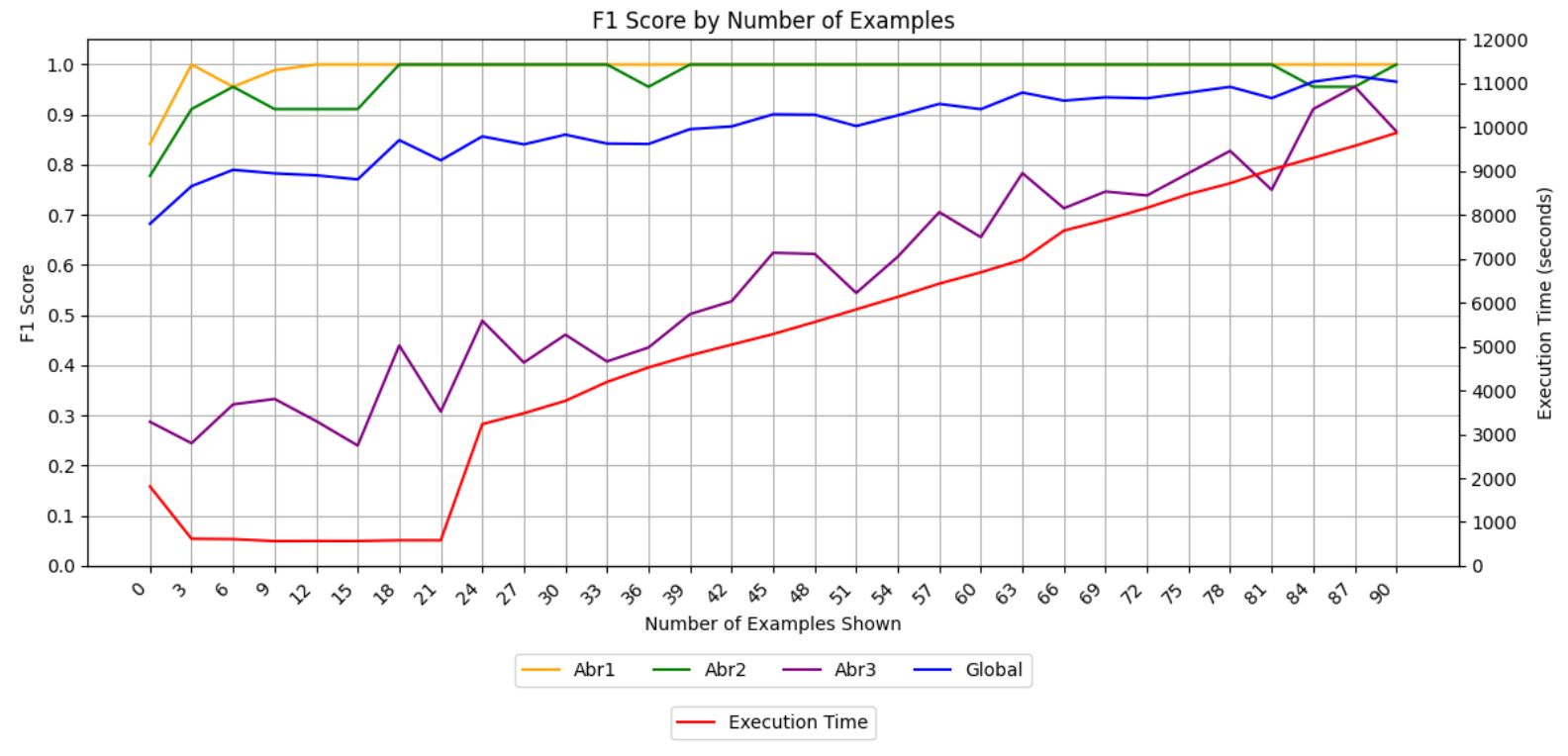
Unstructured textual data from manufacturing environments presents significant challenges for automated processing, particularly due to domain-specific jargon and abbreviations used by operators. We investigate the use of zero and few-shot prompting with open-source Large Language Models (LLMs) to classify operator-generated texts in aircraft manufacturing under data-scarce, high-variation conditions. Our experiments focus on English and Chinese operator texts, simulating three real-world technical shorthand scenarios, and evaluate four models: Mistral, Llama, Gemma, and Qwen. We show that Gemma and Mistral consistently delivers the highest few-shot accuracy for English and that providing additional examples beyond a small set yields diminishing returns. Moreover, few-shot prompts not only accelerate response times compared to zero-shot but also maintain accuracy, whereas Llama and Qwen tend to hallucinate or deviate from exact expected outputs when example counts exceed a critical threshold. When handling Chinese text, Mistral struggles to accurately recover short abbreviations. These results identify a practical “sweet spot” of 3–12 examples for deploying lightweight, locally deployable NLP tools in industrial settings, balancing accuracy, speed, and reliability.
Pierrick Bougault, Thomas Adler
