Reservoir Computing for Sound Classification 🔊
Published:
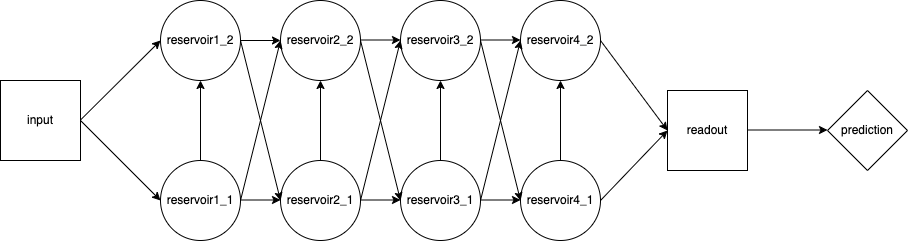
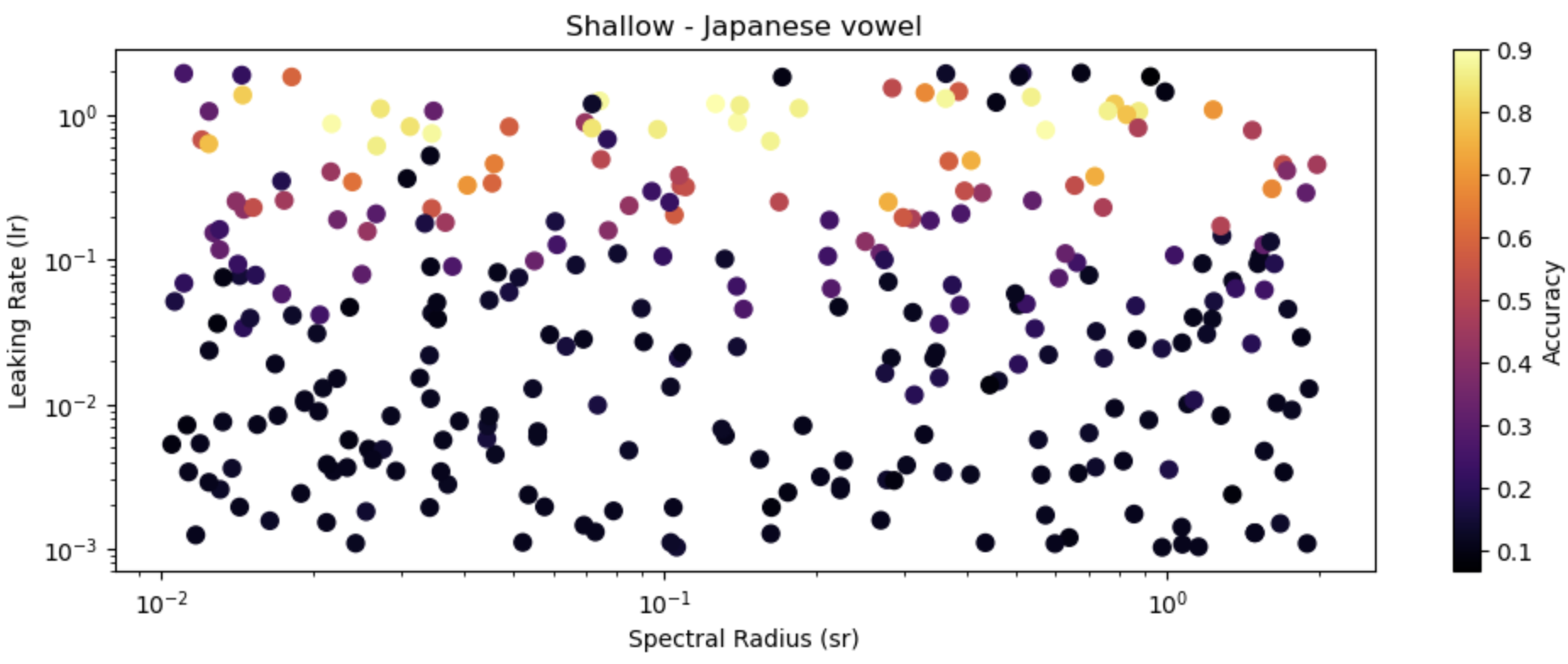
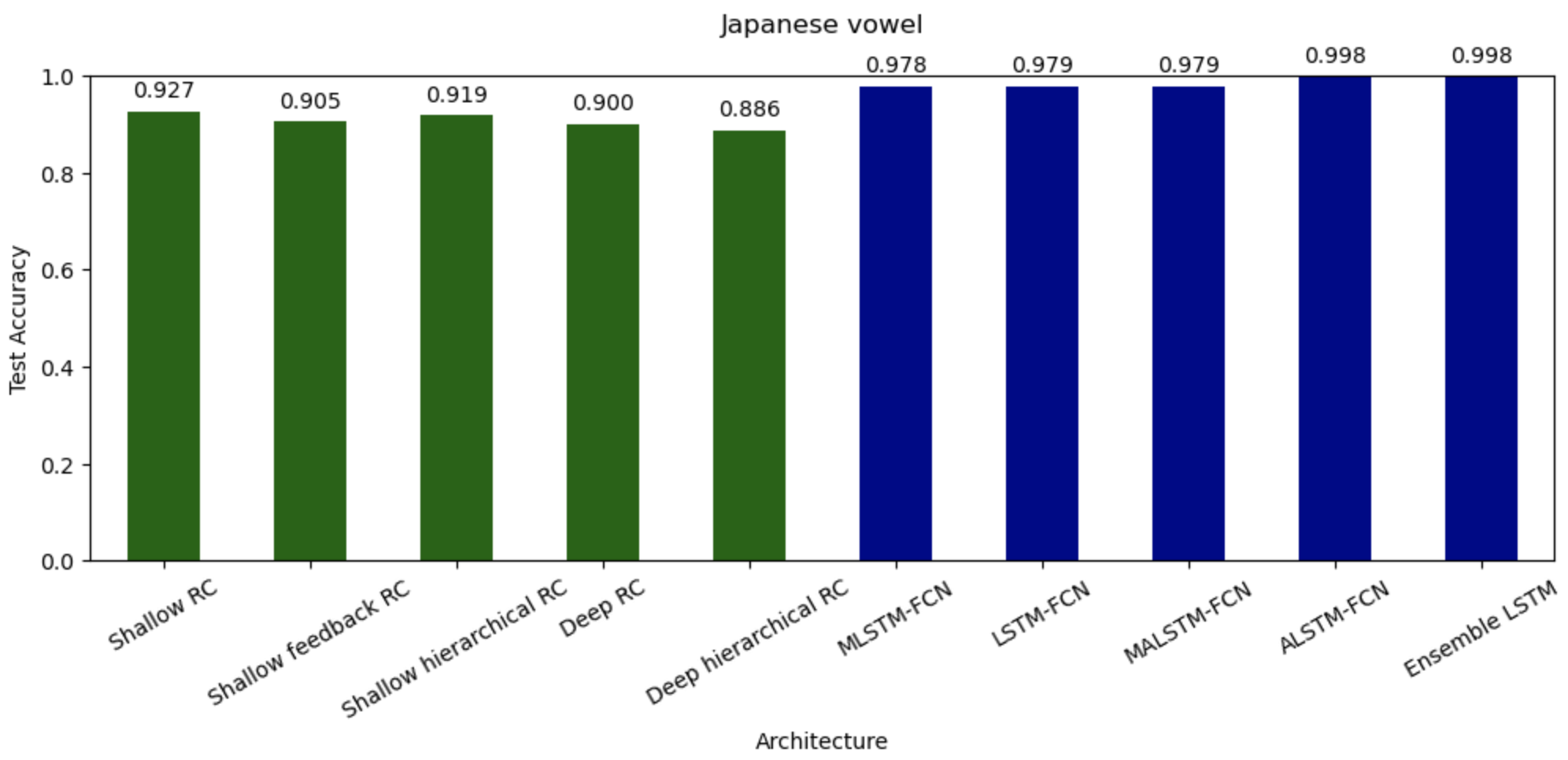
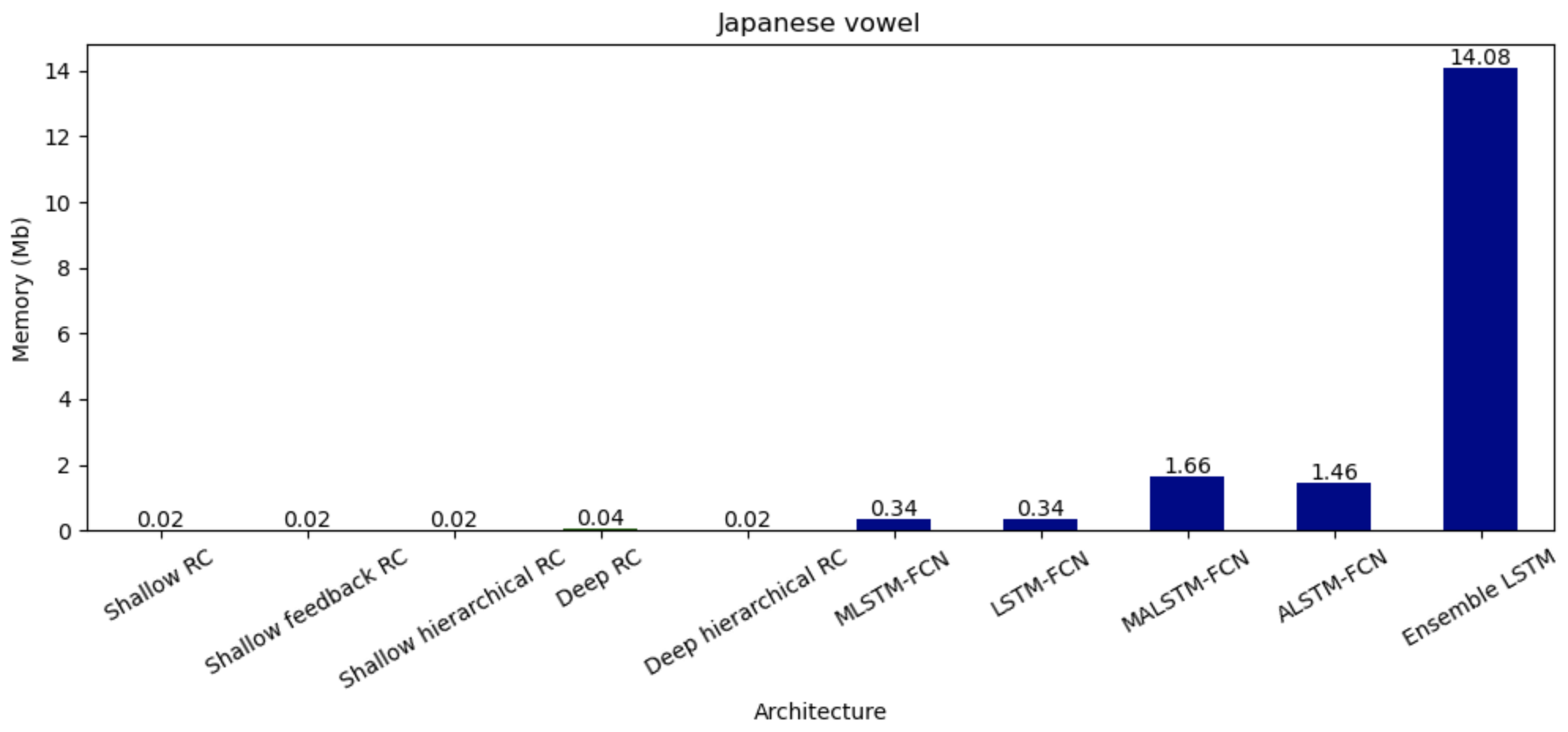
In the recent decade, deep neural networks have outperformed all predecessors in sound classification tasks at the expense of tremendous computational and memory overhead. As an efficient alternative, Reservoir Computing requires substantially less resources than standard RNNs by using fixed, randomly initialized reservoirs and a conceptually simple, trainable readout. This work applies RC architectures to sound classification and compares their performance with deep neural networks. We show through experimentation and hyperparameter tuning on the Japanese Vowel and ESC-50 datasets that RC achieves competitive accuracies at substantially lower computation cost and memory footprint. While a few deep models show better accuracy than RC, the minimal training time with reduced storage of the RC renders it suitable for real-time analytics and deployments on resource-limited systems. These results emphasize RC as a promising strategy for efficient and scalable sound classification, opening future perspectives in ASR on edge devices.
Nicolo Micheletti, Diego Cerretti, Thomas Adler