
Graphing Complexity: Designing an Awesome Graph Database in Neo4j - Part 2 🔗
Published:
“The whole universe is based on the concept of graph theory where love is an edge, that is connecting two vertices or people either directly or indirectly.” - Yatin Mehndiratta
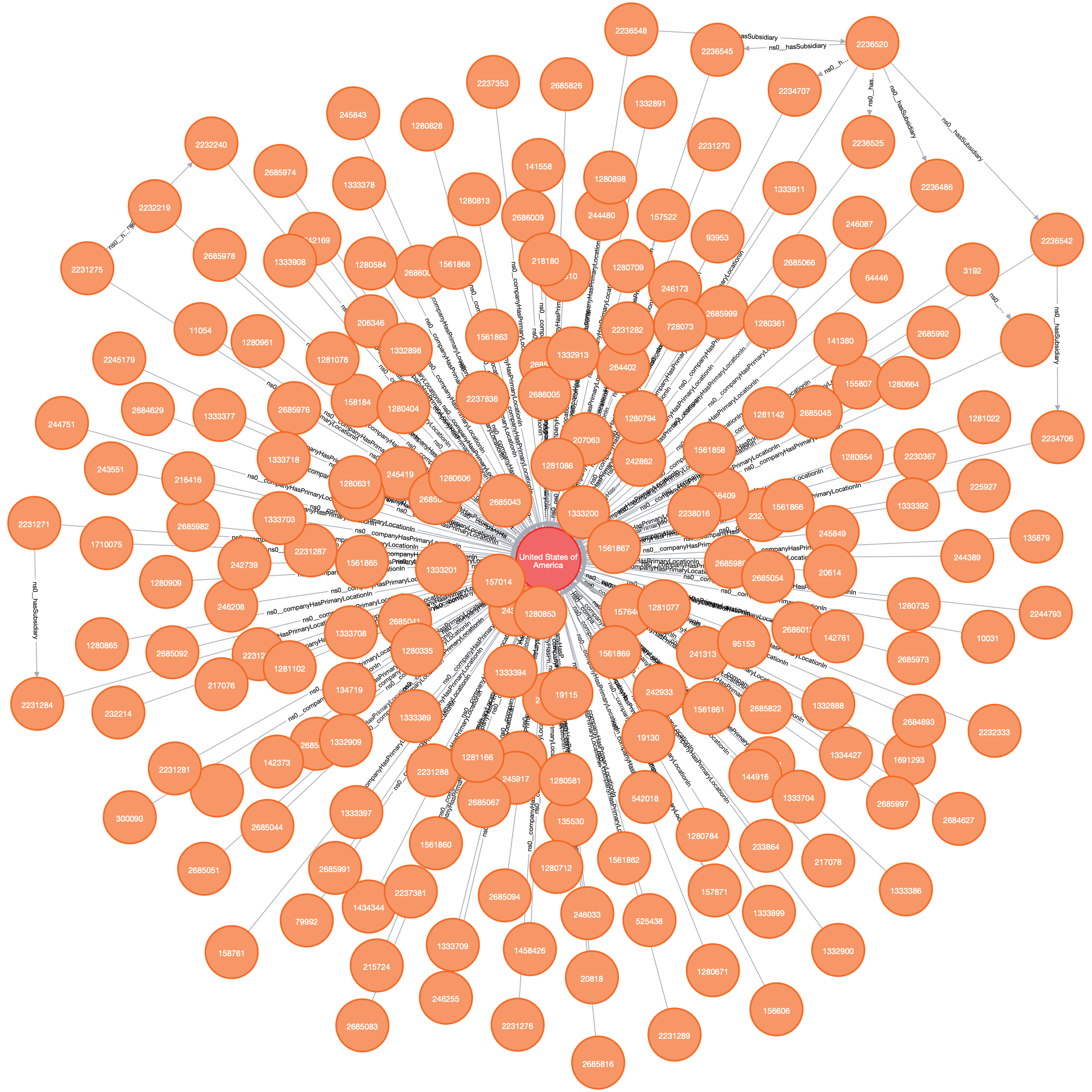
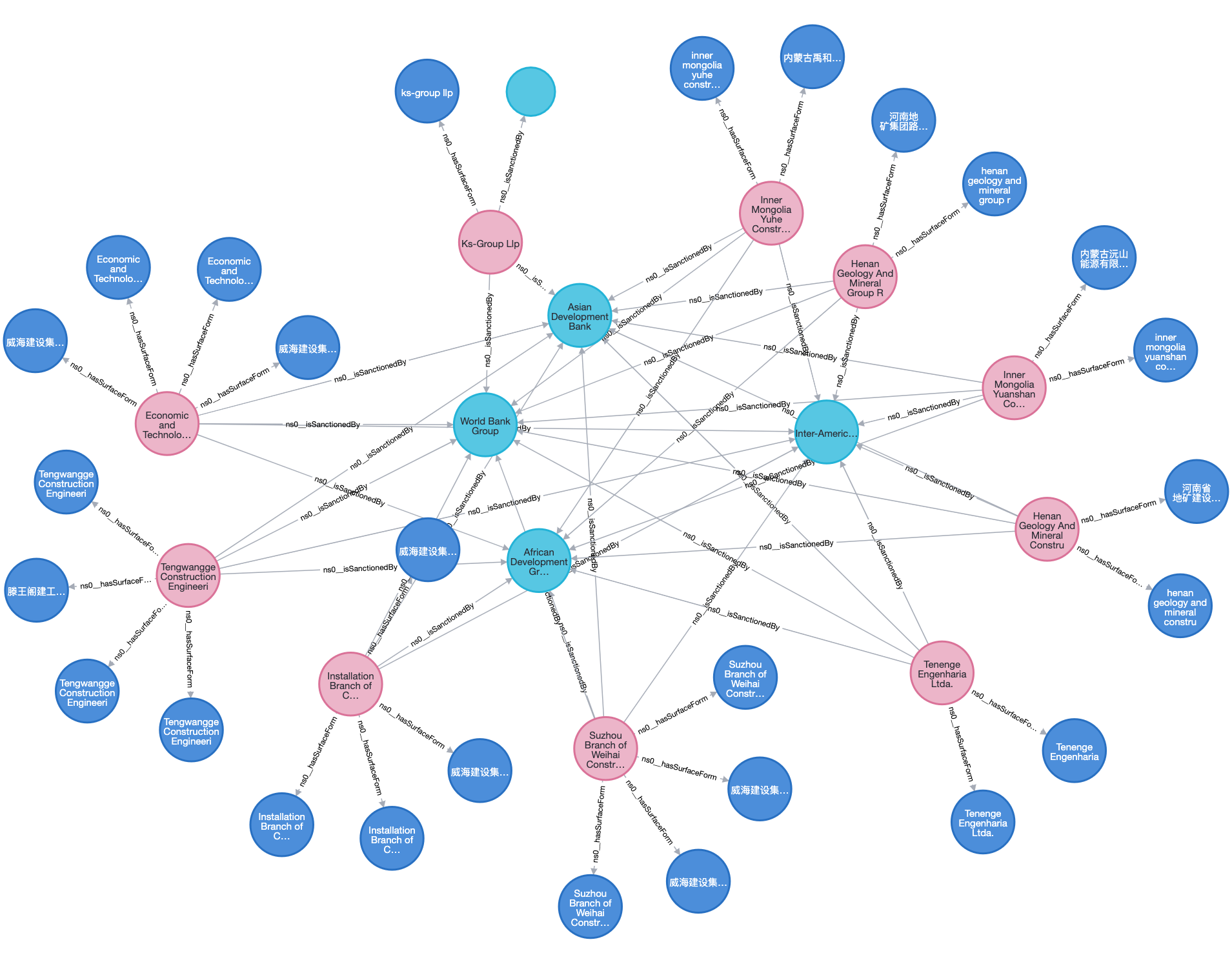
Data from OpenSanctions.
In the first part we introduced the strengths of a Graph DB and the design decisions arounds nodes and relationships.
This is Part 2 of a two-part series on modelling a Graph Database (Graph DB) in Neo4j, here is Part 1.
3. Labels
Every node has zero or more labels and usually represents roles. It represents a Boolean: this node is a Person or is not a Person. Labels are used for low cardinality categorical variables or when categories can overlap; Person:CFO.
The advantage of labels is that they provide fast lookup in a cypher query because they are just filtering for the presence or absence of a label. Labels can be used to partition graphs into sub-domains, group nodes together, and create indexes and constraints on specific groups of nodes.
A good practice is to label every node without exception. Additional labels should always have a query use case, don’t blindly label entities, and create a label overload. Importantly, multiple labels should be semantically orthogonal and independent of each other. Avoid class composition relationships with “nounverbers” such as CarOwner.
4. Properties
Properties are metadata attached to a node or relationship with a Key:Value pair structure. Null is not a valid value, and they represent entity attributes for nodes and relationship quality for relationships.
Properties support constraints; for example, all nodes must have a unique “name” property, and properties are suitable for frequent change of information. You should avoid properties that have a complex value type if the value type has high cardinality or if you’re trying to group nodes based on a property value.
It is best to use a simple value type so as not to burden queries that filter for properties. A small property lookup on nodes can be quicker than traversing relationships. However, this does not hold if you lookup many small properties or if properties are large strings or arrays.
Information should be kept as a property, and not created into a node, if we don’t need to evaluate/filter that information during a graph traversal. However, if it does get evaluated, performance will be affected, and a node should be created instead. Indeed, traversing through a node label is easier than evaluating properties for each node.
Below are some signs that there are a lack of relationships and nodes and too many or an improper use of properties:
- Unconnected Graph
- Data duplication
- Overly complex queries
- “Rich” properties (complex value types)
- Nodes representing multiple concepts
Tips to make your Graph DB more performant:
1. Constraints
For example, all “name” fields must be unique. This makes your data and any further changes more resilient to design or manual errors. It is a safeguard against data inconsistencies, which might come from erroneous data sources down the line.

2. Unique identifiers
Avoid using Neo4j’s built-in IDs; they don’t represent anything tangible. Instead, create your own unique identifier to filter for nodes easily. Then, create an index for your own unique identifier.
3. Indexes
Indexes enable lightning-fast lookups. An index is a copy of some of the data in the database to make queries more efficient. For example, creating an index can reduce the lookup time for a specific property to an O(1) operation by using an extra hash table. Be careful; this comes at the cost of additional storage space and slows down write operations. Choosing what to index or not is important and should be considered carefully. Only index information you query a lot. Usually, these are unique identifiers.
Types of indexes in Neo4j are:
- Range Index –> properties
- Text Index –> string properties
- Lookup Index –> node labels/relationship types
- Point Index –> point (coordinates) properties
- Full-text Index –> full-text search, combining the Range and Text Index

4. Date your changes
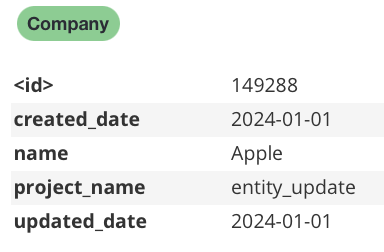
Your workflow for data imports and modifications should enable users to clearly see which data has been created/modified, when, and by whom. This can be done by adding properties to nodes and relationships, for example, created_date, updated_date, and project_name.
Reverting changes and correcting mistakes is now easier because we can map these changes to a time period and project. Since these properties are divorced from the semantics of the node/relationship type, they can be used everywhere.

A good initial structure will avoid breaking changes in the future. Here are some examples:
1. Non-breaking change – Adding new relationships.
Into:
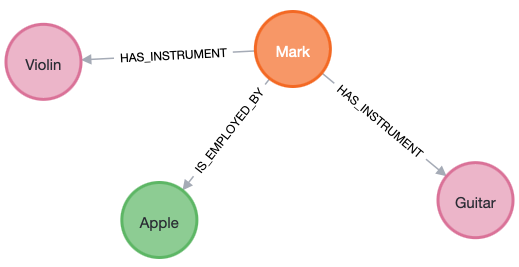
2. Breaking change – Pull out a new node from an existing node.
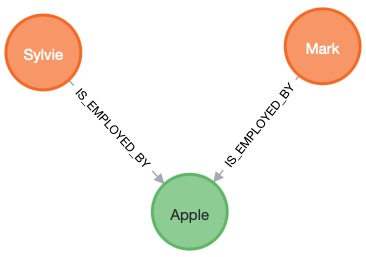
Into:
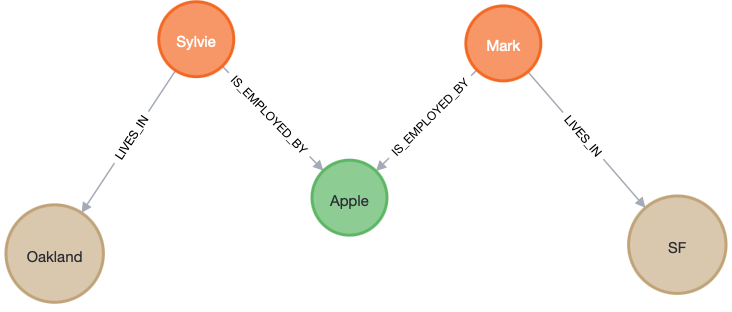
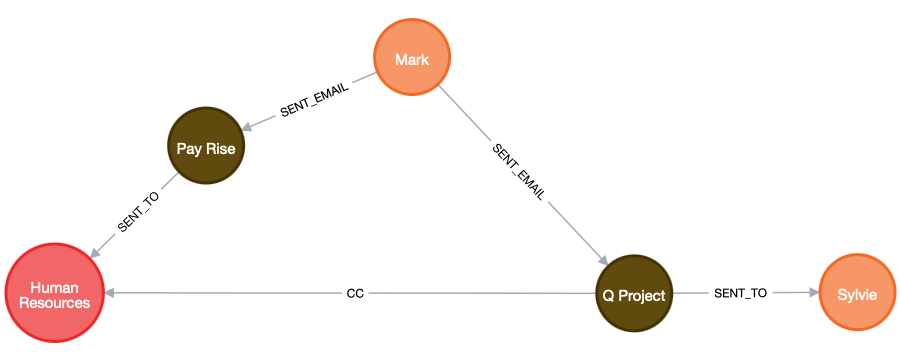
3. Breaking change – Pull out a new node from a relationship.
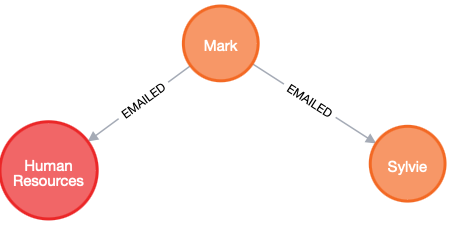
Into:
To summarize,
Create nodes for things:
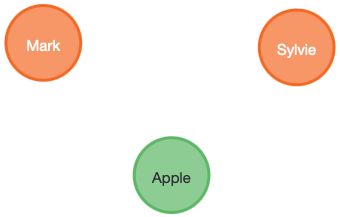
Relationships for structure:
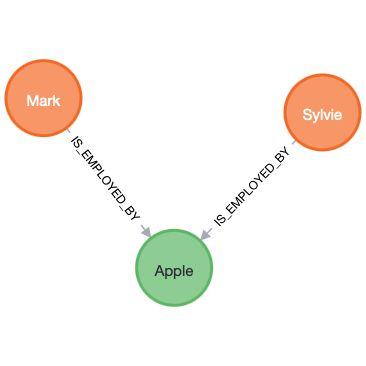
Labels for grouping:
The Person label:

and the Company label:

Designing a Graph DB is more of an art than a science. A lot of the design decisions will be based on the specific business case, the type of data you have, how often the data might change, and the type of queries that will be run. My final advice is always to test your assumptions about performance, space, and time complexity to compare various design trade-offs fairly. Flexibility, efficiency, and simplicity are the most essential qualities of an awesome Graph DB.
If you are interested in learning more about Graph Databases and Knowledge Graphs don’t hesitate to reach out on my LinkedIn or through YUKKA Lab.